在当前的人工智能领域,预训练模式的语言模型LLM和生成式人工智能(GENAI)技术正在快速发展,并且应用成本大幅下降。这种技术的成熟不仅提升了个体的能力,也显著增强了团队效能。在这样的技术背景下,我们需要重新考虑人类和机器在个人成长、发展以及工作环境中如何更好地相互补充。基于对个人知识管理的日常应用经验,以及对各类产品的深入体验,从个人需求出发,我进行了一系列的思考和整理,并希望与大家分享并探讨这些见解。
以语言模型为基础GenAI驱动的智能知识管理系统可以称为系统三
(delle-3生成 )
在讨论决策过程和人类大脑功能时,心理学家丹尼尔·卡尼曼在其著作中区分了两种思维模式:系统一(直觉性、快速、自动的思维)和系统二(缓慢、理性、逻辑的思维)。系统一主要负责快速、基于直觉的决策,而系统二则处理更加复杂、需深思熟虑的决策。
若引入大型语言模型(LLM)基础设施作为辅助决策工具,可视为新增的一个层次,将其视为“系统三”,这一系统可以被看作是辅助决策工具,为人类决策过程提供知识支持、数据分析和逻辑推理,重重复性工作的自动化处理,以及复杂来源的数据和信息的自动化整合。
在此框架下,系统三可能不直接参与决策,但通过提供信息和分析来增强人类的决策能力。系统三并非独立于人类思维之外,而是作为对人类决策能力的扩展和增强。通过提供信息、建议和数据分析,它辅助人类决策过程,但最终决策仍由人类(系统一和系统二)做出。这个层次,或称为“系统三”,在知识管理和决策支持中扮演着重要角色。
系统三的特点包括:
信息获取和管理:快速检索大量信息和数据,协助用户理解复杂问题。
数据分析和模式识别:处理和分析大数据集,识别趋势和相关性。
增强决策:提供基于数据的见解和建议,支持更有效的决策过程。
因此,将基于语言模型的工具视为“系统三”,意味着它代表了人类思维的一个有力补充,尤其在处理复杂和数据密集型问题时尤为明显。这种模型强调了LLM、生成式AI等人工智能技术在辅助人类做出更佳决策中的角色。它们能够快速处理大量数据,提供洞察力和建议,但最终的决策仍由人类(即系统一和系统二的思维模式)做出。
此外,实施系统三也带来了一些重要问题,如透明度、可解释性和道德考量,这些都是在将这些工具应用于实际决策过程中需考虑的因素。
原文太长2万2千字,围绕如下议题,这篇post仅聚焦于系统三论断,阅粒搜藏智能知识管理方法论的迭代、 以及 思辨逻辑的。全文自主撰写框架要点和中观点,由chatGPT优化输出。感兴趣枯燥装X的全文可以访问我飞书的 链接。
什么是知识
提起知识管理,首要任务是明确‘知识’的概念。知识不仅是信息和数据的集合,是通过吸收信息、积累经验,以及理解前人智慧而获得的宝贵资产,更是对这些信息的深入理解、分析和应用。它包括从书籍、经验和观察中获得的事实、概念、经验、原理认知和程序。
有效的知识管理不仅涉及信息的收集和整理,还包括知识的创造、分享和应用,知识管理强调通过系统地学习和理解,我们可以将这些信息和技能内化为个人或组织的智慧和能力,从而促进发展和创新。
知识从可感知支持深度洞察分析角度,可以分为显性知识和隐性知识两种,
- 显性知识:可以用语言或其他形式明确表达出来的知识,比如书面文件、数据库、手册等。这类知识较为直观和形式化,易于传播和共享。
- 隐性知识:难以用语言或其他形式明确表达的知识,存在于人的头脑中,比如经验、技巧、知识等。这类知识较为主观和隐晦,不易传播。更多的体现为关系、相关性等。知识管理就是针对这些知识的创造、获取、存储、共享和应用等进行有效的管理,其目的是最大限度地利用组织内部各种知识资源,提高组织效率和核心竞争力。
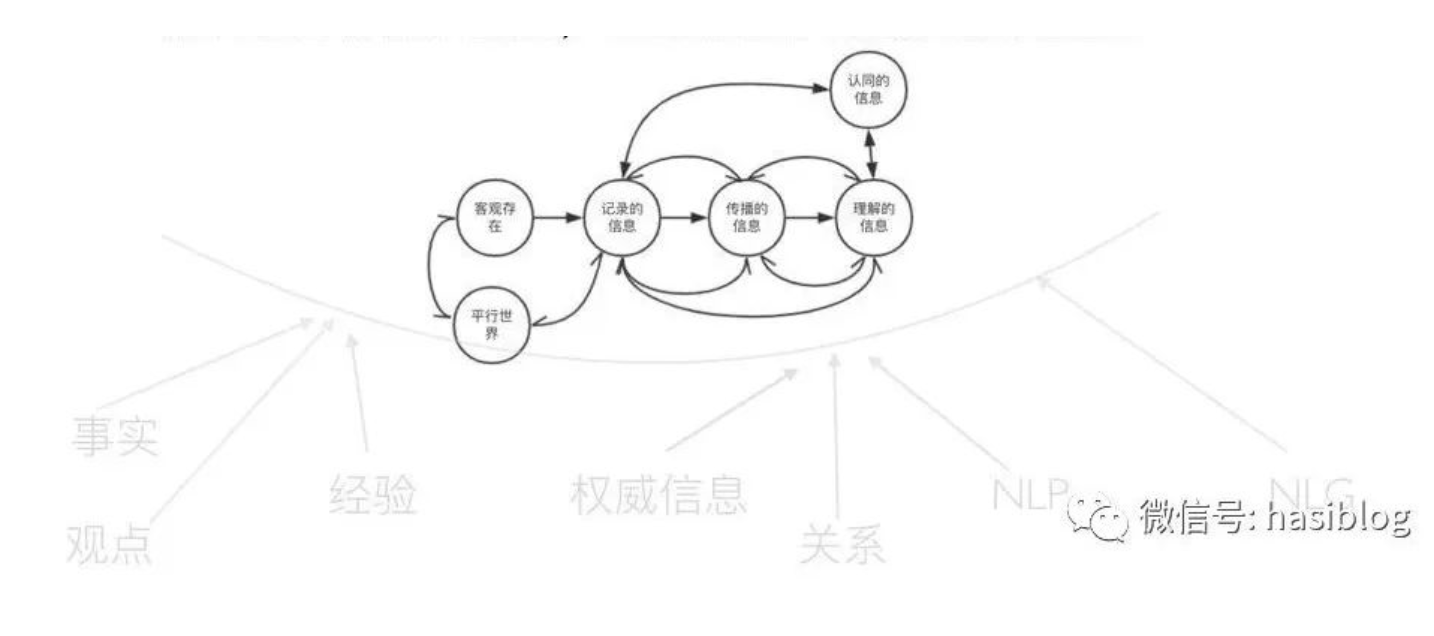
从信息的记录、传播、理解和应用角度,又可以分为客观信息和非客观信息,
“客观世界信息化”过程包含了对客观世界的概念化、状态表达以及符号化编码,这非常精准地概括了信息生成和知识创造的过程。之前分享的时候经常用的一个概念图,描述产品经理如何通过观察一些现象的共性来形成产品概念的过程,是客观信息通过“角色化”“场景化”的重构,形成知识得到决策的一个演绎。
具体来说:
1. 概念化是根据认知主体对客观世界的理解,形成对事物及其属性的概念。这是信息生成的第一步。
2. 状态表达是用语言或图形等形式描述客观世界中事物及其关系的具体状态。这是将概念具体化表达。
3. 符号化编码是使用符号系统(如语言文字、数学公式等)对状态表达式进行编码,生成可记录、传播和处理的形式化信息。信息和知识的产生就是这样通过主客观互动,从认知到表达,从概念到符号的过程。“客观世界信息化”很好地提炼出这个过程的三个关键要素。
LLM通过预训练阶段通过大量的高质量数据和训练语料,已经实现和符号化编码的预处理,就是tokenized,并且融合了训练语料中这些token之间的关联、依赖关系。
我们把客观现象的抽象概括事实、经验、程序/逻辑、观点、权威信息、原理、数据,几种抽象的知识概念,将现象抽象为这些知识概念,将这些分散的知识点进行收集、整理、编码,是知识管理的主要工作之一。使它们形式化并可以被有效保存、获取、共享和应用,将为个人学习成长和组织应用提供极大便利,从而提高组织的知识资产化。这一点是知识管理的起点,关于知识的发现2020年层分享过
知识管理的算法 ,这对我们理解和管理知识的生成与表达也具有很好的启发作用。
从知识管理的可操作来看
在知识管理领域,我们通常关注那些可显性表达、可编码的信息和数据,以此作为主要对象进行知识的表示、存储和应用分析。具体来说,知识管理主要涉及以下几种类型的知识:
文字性知识:包括各类报告、方案、文件等,这些知识可以通过文字、图表等形式进行表达,属于显性知识的范畴。
结构化数据:例如数据库、电子表格中的数据。这些知识通过数字和符号编码,可以被系统化管理。例如,我在百度工作期间,曾经参与做过结合垂直数据库和全文检索系统的搜索引擎应用相结合的产品(https://blog.loverty.org/2009/03/blog-post.html),这个技术方向最终最终演变成了各种百度阿拉丁产品。
程序性知识:如组织内的业务流程、操作规程等,这些知识可以被标准化、制度化,以明确的流程和规范表现。
经验性知识:工作中员工积累的经验和技能。虽然这类知识较为隐性,但可以通过记录和分享等方式进行管理。
相比之下,更为个性化和隐性的知识,如直觉和洞察力,确实较难直接管理。
知识管理的目标是尽可能地将这些隐性知识显性化和形式化,使其也能成为可管理的对象。
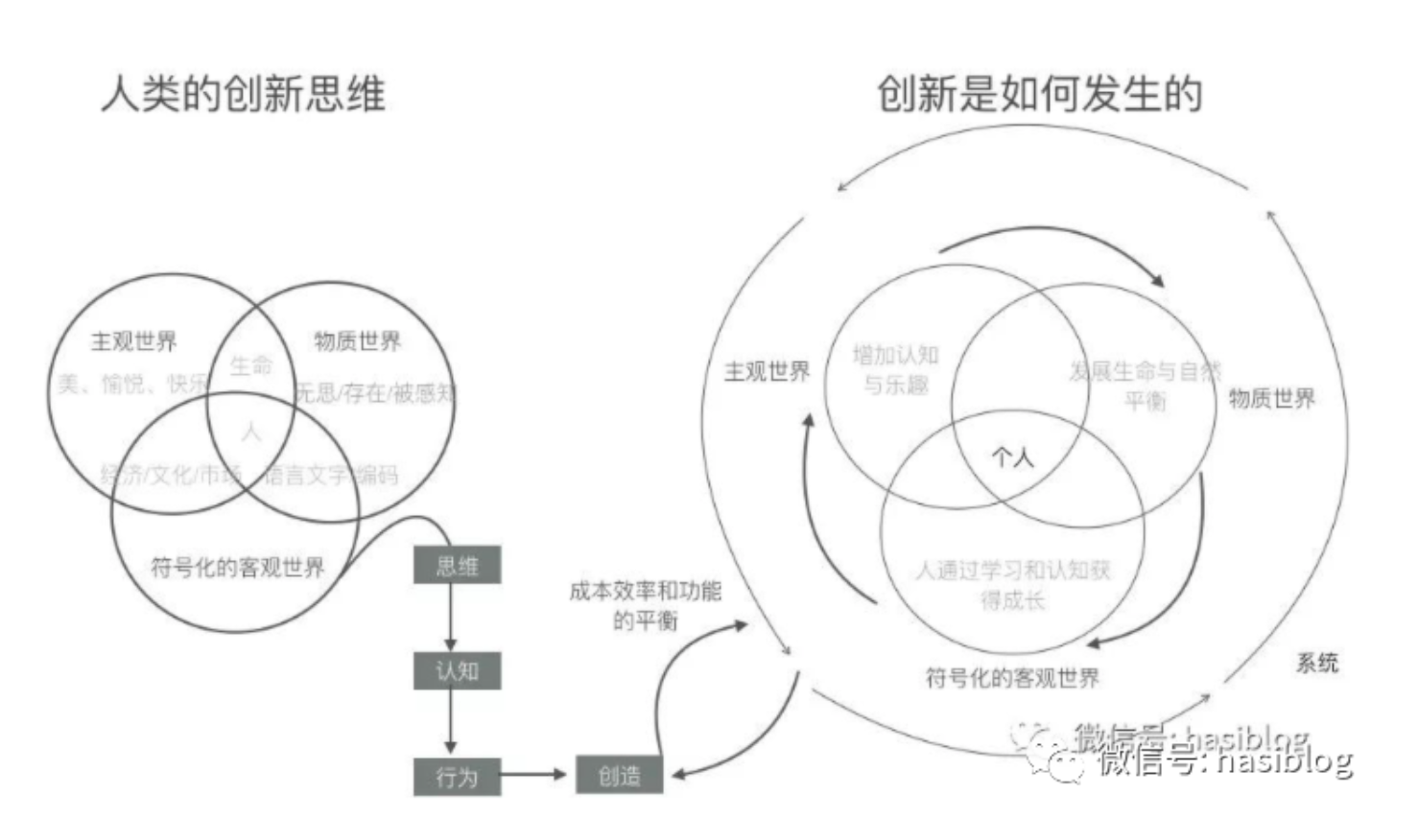
Paul Graham文章中的观点,在工业革命之前,知识当然确实具有实际作用,作为体现为对世界的理解和智慧,直接作用于人的行为和生活中。而工业革命之后,知识被组织化和系统化,成为了一种被编码的资产,可以传播、积累和应用。更多的普通人如果掌握了系统化的知识,也可以产生很大价值。这也是知识管理存在的价值所在。它将分散的个人知识,通过整理、编码、组织,转化为系统性的知识,这样更多人可以共享和运用知识,从中产生价值。
随着技术的不断进步和市场交易的发展,社会逐渐步入了资本主义、个体自由主义和信息时代,这些变革使得知识逐渐成为一种显著的资产:
技术进步使知识可以被编码和存储,转变为可交易的商品。
市场交易的发展赋予了知识明确的价值,使其成为可以买卖的对象。
资本主义和自由主义强调个体价值,使知识成为个人竞争力的关键要素。
信息时代显著降低了获取知识的成本,使知识成为最重要的生产要素。
在这样的大背景下,知识管理作为一种管理理念应运而生,其核心在于系统化地管理知识,以便个体和组织能够最大限度地利用知识资产,提升效率和竞争力。知识管理反映了知识社会的发展趋势,它将依赖于非系统化的个人知识转变为对系统化知识资产的管理,体现了知识的资产化和商品化。同时,我们也应认识到,系统化知识的局限性。为了真正产生超线性的价值,我们需要依靠个人的创造力和智慧,而不仅仅是现有知识的应用。知识管理的目标不在于取代人类的智慧,而在于辅助和放大人类的智慧。
在LLM为基座的智能知识管理阶段,个人知识管理体验上已经不再依赖传统的分类、目录、标签这样的格式化、显性化的组织形式,更多是注重信息筛选和质量评价,以及你在把这个信息知识化过程中,对他的提供的性化的知识进行增强,比如你的观和关注的问题,类比和关联的知识和信息等,作为对该内容知识化的补充。LLM更为擅长的是为你解决“已知的未知”。
一种显著增强特定知识的方法是通过构建个性化或主题化的知识库,并利用RAG(Retrieval-Augmented Generation)参与的大型语言模型(LLM)来响应您的提问和互动 。这种增强过程实际上融合了应用和评估,使得你能够在互动中持续进行知识的捕捉、验证和增强。在这个过程中,你构建的知识库不断被访问和利用,以回答具体的查询和问题。LLM利用其高度发达的理解和生成能力,从您的知识库中检索相关信息,并结合当前的交互上下文生成回应。这样,每次互动都成为一个机会,不仅用于解答问题,还用于验证和增强知识库的内容。更进一步,您在与LLM的互动过程中所获得的新知识和洞见可以被再次整合回知识库中,形成一个动态发展和自我优化的系统。这种方法的关键在于,它将知识管理转变为一个活跃的、参与式的过程,而不仅仅是被动的信息存储。这不仅提高了信息的实用性和准确性,也增强了个人对于信息的理解和应用能力。因此,这种方法极大地提高了知识库的有效性和适应性,使其成为一个不断进化和反映最新知识的资源。
随着新一轮AI变革的到来,知识管理和思维扩展的方法将不断演进。保持开放的心态,积极尝试新工具和方法,以不断提高工作效率和创造力。这将帮助你个人更好地应对信息爆炸时代的挑战,并更好地扩展大脑思维与记忆的边界。
制定适合你自己期待的用途和目标的知识管理策略,比如围绕你目标展开信息重要性分层,以决定哪些是要进入你的系统1、系统2成为内在的知识和智慧,
围绕不同分层信息,建立知识管理助力成长的策略,比如适合信息进入系统1、系统2的采用SQ3R阅读法、达芬奇的笔记、西蒙学习法、费曼学习法等。如果是信息资料参考数据类就适合存储在系统3,当作资料,随需要来查询和调用。
知识发现机制,比如通过笔记平台记录、自动化或半自动化采集网页、feed、email等,确保这些工具能够无缝协作,以支持你的知识组织、管理和扩展。
利用大语言模型:利用大语言模型(如GPT-4)进行智能对话,以更深入地理解和解释知识。这些模型可以帮助回答问题、生成内容,以及将不同概念连接在一起,从而激发创意和扩展思维边界。
将你的知识库与LLM模型服务的外脑集成:将大语言模型集成到工作流中,以提高知识管理的效率。使用外脑系统,将外部知识库与大语言模型连接,以进行更智能的搜索和信息检索。比如MEM,base在openAI model上的智能知识管理,阅粒搜藏是base阅粒模型,并且支持连接ChatGLM、文心一言等国产优质大模型服务智能知识管理系统。
基于大模型产生的创意激发和能力扩展,比如阅粒搜藏支持的六顶思考帽的模式,针对同一主题和话题的创意延伸和拓展。他不仅意味着你有大量机会通过情景模拟,去思考多种不同角度对于同一问题的思考,还可以通过不同视角引入更多的上下文信息,让LLM通过多重模拟、演绎来实现对你的问题更深刻的分析理解和解决。
该prompt是在GPTs上创建的基于阅粒搜藏知识管理方法论的bot
https://chat.openai.com/g/g-r18kjYe0P-yueli-socang
LLM驱动的GenAI可能会有助于解决“未知的未知”
由大型语言模型(LLM)支持的GenAI呈现出解决“未知的未知”难题的潜力,挑战现有的解决方案并重新定义问题解决的范畴。在探索最优方案的道路上,GenAI的进步为我们提供了新的视角和可能性。
生成式人工智能GenAI辅助个人问题解决案例的研究
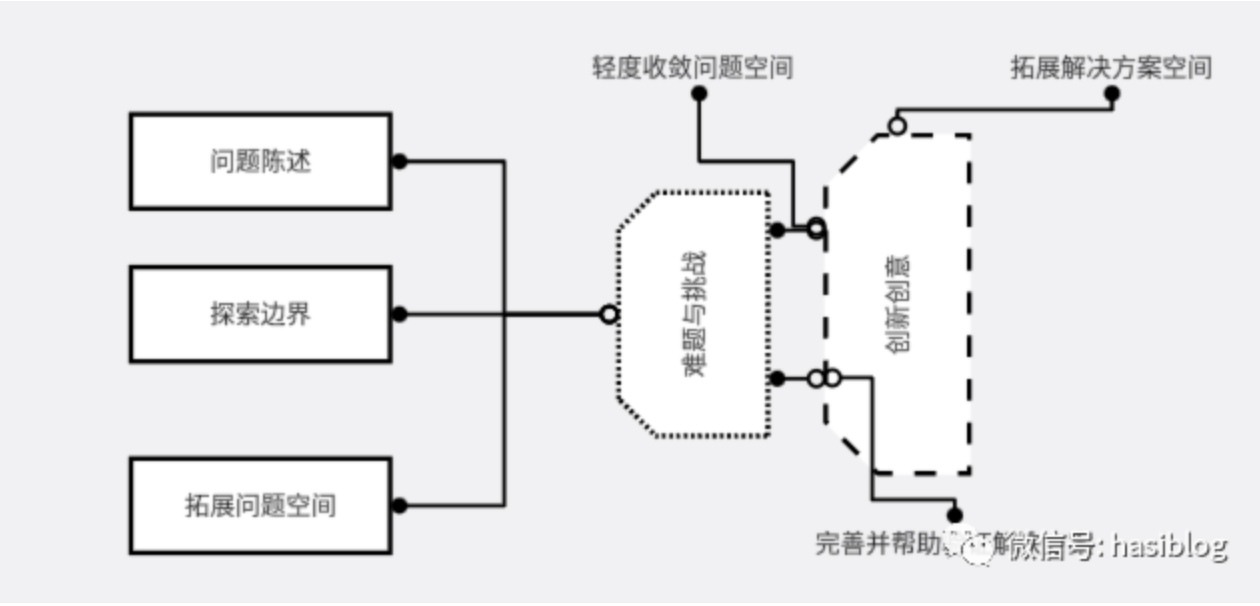
通常情况下作为知识管理工具,是如下操作流程
生成式AI参与分析和解决问题,流程变成了
如上图所示的流程揭示了生成式AI的作用机制。在这一过程中,GenAI汲取了大型语言模型(LLM)的语言理解和知识综合能力,通过不断的迭代和交互,基于问题的深入探讨,GenAI不仅理解问题本身,还能够突破传统框架,提出创新的解决方案,从而拓宽问题解决的视野。
在 一个充满信息的世界里,我们的脑海常 常被新的想法和知识挑战。 LLM与GenAI结合:激活你的创新潜能。 在这个以知识为本的时代,LLM和GENAI不仅是信息处理的工具,更是创新的伙伴。它们打开了一个新世界的大门,让我们的想象力和创造力得以翱翔。让我们我们探索知识和创新的旅程中,两种技术显得尤为重要:大型语言模型(LLM)和生成式人工智能(GENAI)已经成为我们智力的超级助手。它们不仅仅是信息处理的工具,更是我们理解和创新的伙伴。它们能够将海量数据转化为有价值的知识,加速我们的决策过程,提高我们的学习效率。
GENAI则像一位点燃创意火花的艺术家,它通过将不同的概念和思想融合在一起,激发出新奇和独特的创意。这种技术的使用不仅仅局限于传统的创意产生,它还能帮助我们打破思维的界限,探索前所未有的解决方案和创新途径。
LLM作为我们的交互伙伴,通过其理解、生成和处理语言的能力,为我们提供了一个交互式的学习平台。它们帮助我们迅速从庞杂的信息中提取精华,让知识更加容易理解和内化。同时,LLM也在个人生产力方面发挥着重要作用,通过优化信息检索和知识管理,极大地提升了我们的工作效率。
另一方面,GENAI作为跨界思维的催化剂,通过整合不同领域的知识和观点,促进了跨学科的创新和多样化思维。它鼓励我们超越传统的思维模式,探索新的思维路径,激发出更多的创新灵感。
总的来说,LLM和GENAI不仅改变了我们处理信息和管理知识的方式,它们也在激发创新、提升生产力和促进跨领域思维方面发挥着不可或缺的作用。在这个信息爆炸的时代,它们成为了我们理解复杂世界和创造新奇想法的强大工具。