*机器人写作,从模版生成、到辅助写作,从语句生成,到长文创作,从各个角度各个姿势都在试,都在试图找到最大价值的承载点。*
人工智能技术(AI)内容生成或者辅助内容生产这件事上,目前有几个典型场景应用类型,生成文章、内容创作辅助工具、生成短文本、写诗、写摘要等,目前市面上已经有不少相关领域的公司,在不同角度探索,而且产生了一定的成绩。
目前机器人写作领域主要业务类型
从目前的机器人写作输出的内容角度划分,主要有这么几种类型:
1,简讯、报道、快讯、报告。
用模板+算法+数据,merge到一起生成文本内容。这类基于数据类文本内容创作,比如目前应用最多的财经、体育、新闻资讯、金融商业等领域,当然这里机器人写完之后,人工会做运营加工和完善,才发布给公众。目前这类市面上比较多。
2,故事和连续语义的创作,比如恐怖故事Shelly(MIT 媒体实验室),openAI文本生成器,还有各类网文小说生成器,在搜索引擎里一找一堆。
3,文本生成创作,比如写诗写对联、拍照写诗,摘要生成、客服会话语言文本生成等短文本生成,目前某些信息流类产品,他的标题就是用短文本个性化生成、有些电商平台也在用短文本生成商品介绍的标题。
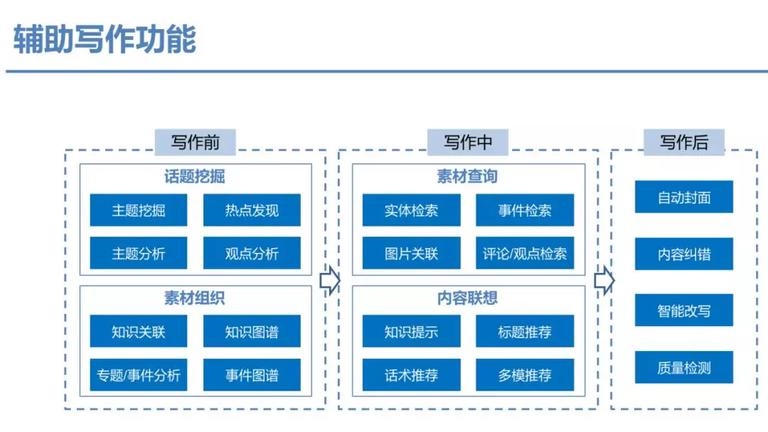
4,辅助创作、写作类,目前也有不少,典型的写作助手、文章查重、标题生成、摘要自动生成、自动纠错、语料和引用提示等。
5,其实目前颇有“建树”的领域是,洗稿、盗版别人的内容、生成低质量的垃圾文本信息去搜索引擎、推荐引擎里混流量,就是你常在某某号和某某号里看到的那种,标题或者配图狂有吸引力、其实内容渣渣的大部分都是。
主要公司的产品及其能力
-Bloomberg的Cyborg写作机器人写财经、通讯类文章,快速抽取商业金融新闻领域数据信息(business financial journalism),帮助信息发布者或者竞争情况消费者及时获取相关信息,在商业竞赛中,为对冲基金人工智能为客户提供新鲜事实fresh facts。
-福布斯Bertie的工具,建立在出版商的内容管理系统中半自动主题推荐功能的基础上,为记者编辑提供粗略的草稿和故事模板,它能根据记者以前的记录、工作生成写作提示,作为写作辅助工具,提升产出效率和质量。
-路透社(Reuters) 推出的Lynx Insights会涉及与报道相关的关键数据,比如,帮助记者快速分析大宗商品定价的历史趋势。
-美联社2014年6月采用Automated Insights的公司开发机器新闻写作,按照美联社商业新闻主管Lou Ferrara的说法,采用基于算法的机器新闻写作后,在无须增加新的人手的情况下,美联社的商业新闻中关于企业季度经营状况的报道量,增加10多倍,从原先每季度300篇上升到4400篇,产生人效14倍的增长。
> Automated Insights(创立于2007年)一家专门从事语言生成软件的技术公司,会为客户、合作伙伴生成大量的通讯报道,他们也做公司的财务收益分析的报道。他们开发的WordSmith的软件,可以自己编写一些简单的新闻事件,比如体育、财经类的新闻资讯。雅虎、美联社的相当一部分新闻就是由这位WordSmith编写的。据Automated Insights公司介绍,WordSmith在2013年生产了3亿篇各类形式的报告,2014年生产了10亿条新闻
-The Post有一位名为Heliograf的内部机器人记者,通过报道2016年夏季奥运会和2016年美国选举,展示了它的实用性。
-新闻机构Patch的写作机器人为其110名员工记者和众多自由职业者提供协助,他们覆盖了大约美国800个社区,特别是他们对天气的报道。该公司首席执行官沃伦·圣约翰表示,内容量的5%到10%都是由机器生成的。
-腾讯写作机器人(Dreamwriter)是由腾讯财经开发的一款自动写作新闻软件,Dreamwriter根据算法在第一时间自动生成稿件,瞬时输出分析和研判,一分钟内将重要资讯和解读送达用户。
-百度智能写作机器人Writing-bots产出的文章主要包括速报类、知识类和资讯聚合类。速报类,如比赛信息、股讯快报等,对时效性要求比较高,需要瞬时将结果生成文章。知识类主要是科普类的文章,如教育(诗词、历史知识)、生活(菜谱,保健知识)、旅游等。知识类文章的数据内容主要来自百度的知识库和全网优质资源,通过对优质数据资源的组织聚合和计算推理,为用户提供更加丰富的知识和信息。而资讯聚合类是基于全网实时资讯数据,根据用户关注点,生成用户感兴趣的、以话题为中心的资讯文章,比如某一个电影热映,我们会对电影的主演、之前的作品等信息做一些扩展和盘点;对于热点事件,我们会对事件的发展过程和关键信息进行分析聚合,形成事件脉络,便于用户了解事件全貌等。这类文章是在现有的资讯信息基础上,重新智能聚合生成新的文章。
-今日头条张小明Xiaomingbot不仅能写体育文章,还有财经、房产等等。财经新闻有「小明看财经」,房产是「房产情报站」,世界各领域热点有「小明看世界」,一系列内容都由这些头条号自动放出。“张小明”在2016年里约奥运会期间报道乒乓球、网球、羽毛球和女足的比赛,6天共生成超200篇简讯和资讯,xiaomingbot能完成2秒之内生成稿件并发布,24小时不休息,产量惊人,大大减少了采编人员的工作量,提升了新闻信息的生产能力。
-第一财经DT稿王(背后是阿里巴巴),2016年发布的DT稿王,其“任职”是通过海量抓取、海量分析,主要针对上市公司公告、财务报表、官方发布、社交平台、证券行情等信息源,日阅读3000万字,针对内容做精简输出,把几千字的文章转换成一两百字的重要概括,大大提高效率。
-“快笔小新”2015年11月7日新华社推出写稿系统正式运行,实现了采编业务与技术手段的深度融合,适用于体育赛事、经济行情、证券信息等快讯、简讯类稿件的写作。
-南方都市报的机器人“小南”,撰写的第一篇稿件是关于春运车票动态信息。2017年1月18日正式“上岗”的小南,由智媒云图和北京大学计算机科学技术研究所联合成立,对机器写作、文本实体识别、智能摘要、立场分析、智能服务等方面进行研究和实践。小南基于机器学习算法、自然语言生成技术和自动摘要技术,通过融合领域知识,对数据进行深度分析,发掘重要的消息和事件,并用自然语言进行表达,从而以秒速生成报道。写作领域涉及民生、科技、财经、体育、娱乐、消费等领域。最终实现多领域的自然语言智能理解和自动生成。
几种典型技术方法
--深度学习方法,机器在阅读了大量的古诗、对联的基础上,基于我们的NLP分析结果,通过“平仄”作诗、写对联的规则自动生成。这个结果是成诗有韵,但是缺乏内在的精神内核。曾经在2017年Q3做过一个这个方向的小产品。
--模板生成,机器人在自动抓取的情报中按照预先设定的结构写稿,成稿速度非常快,但它不能分析新闻事件的原因和影响。其基本的设定都是,人工准备素材、模板,设定条件,机器自动创作。其中素材的采集、模板讨论、创作运行条件这些都还是需要大量依靠人的工作。
> 今日头条的,xiaomingbot是关于比赛的实时比分的数据通过文法结构和模板生成。对于图片,通过计算机视觉分析图片内容,将它和文字结合匹配出来。第三方面是知识库的建立,像比赛球队的历史、球员信息,作为额外信息补充进去。第四,是网上有一些直播文字抓取过来的信息,通过机器学习里排序学习的技术去挑选最重要的内容,融合进文章中。网上的直播文字信息其实非常复杂,有不重要的信息,甚至会夹杂网友的评论。我们在生成新闻的时候希望把比赛最重要的环节,像进球、判罚等等给找出来;另外,需要考虑挑选出来的句子相互之间相似度要尽量小,但涵盖信息量又尽量大。通过 DPP 算法可以有效找出直播中的重点信息且涵盖最大的信息量。
--当然第三种,就是用算法+规则混搭,不同场景路由到不同策略上。由特定场景和领域特殊约束来界定有某种方法做内容生产、加工或者输出。
--还有第四种,算法就作为人工的辅助,在帮人做素材发现、图片图表的生成、对比分析的可视化、关系联接,甚至结构定义、表达纠错、优化上都能够给出建议和参考。
资讯内容的机器人写作在特定领域还是有很多价值,局限于技术和算法的实现能力,大多数场景还是人工+规则+算法来完成。
**机器人写作的一般过程**
任何一篇由算法驱动的“自动生成”的文本创作类写作流程分以下几个步骤:
1,获取数据、信息输入。理解消化关于数据和写作输出物有关系的各种数据,并能从各种形式的数据和素材中找到跟目标输出物有关的数据、信息。他可以是APIs、也可以是各种格式的数据、算法、服务。
2,分析数据,解析数据以及其内在关联、关系以及找到合理的数据结构表述,对数据及目标输出的表示进行归纳
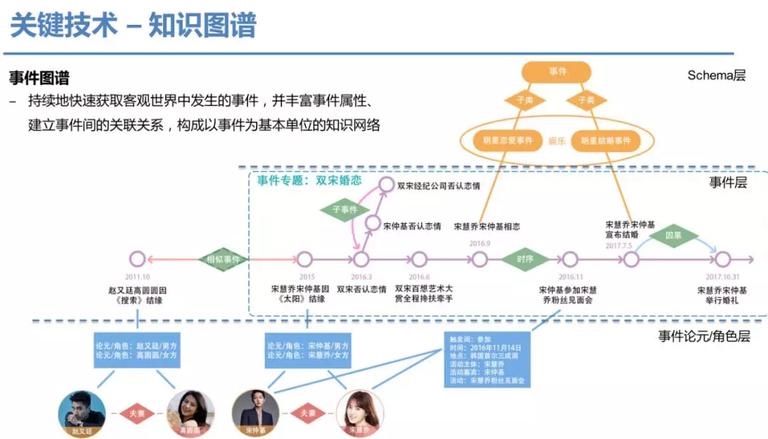
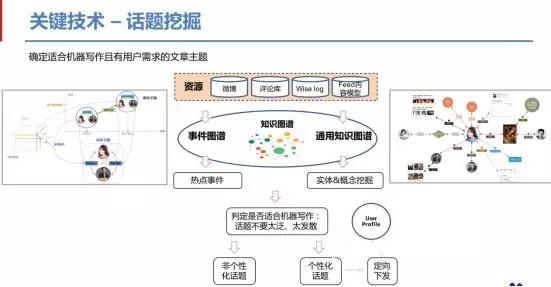
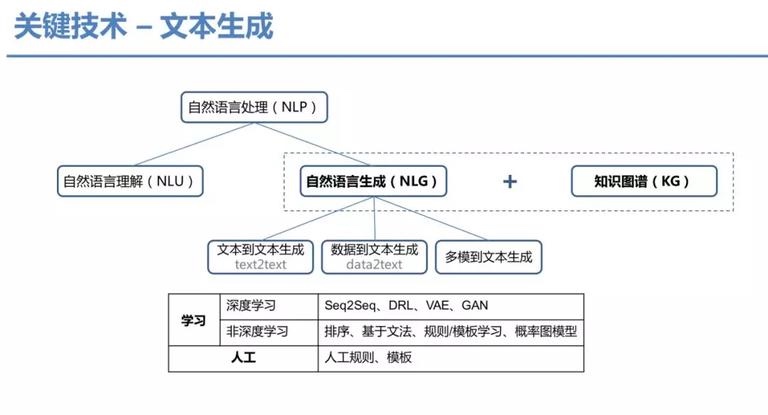
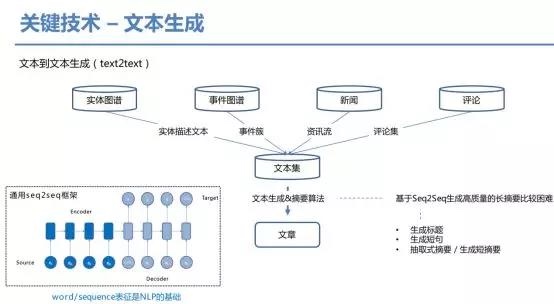
3,构建输出结构,对于不同类型和目标诉求的输出物,要求在输出结构的定义、输出结果的语义表示上进行合理化表达,当然引入用户画像进行个性化表达是更合理的。而进行语义表示则离不开知识图谱的约束或者支持,把数据放在输出对象的知识图谱背景框架下表示。
4,展示优化,遣词造句、语言修饰,是否用可视性元素装饰等,比如特别典型的这几种场景闲聊会话、长文、摘要、短新闻、通讯报道、故事、可视化图表为主的内容、微博、标题等。不同应用方式,优化的方向和方法也是不同的。
5,根据内容特点,选择内容出版分发通路,并且自动化输出到对应的媒介上,个性化展现、个性化分发,传递价值到用户和消费端。
**机器人写作的价值**
1,写作输出事实性确定性好,且出错率更低。
2,生成内容速度更快,时效性内容追踪速度大大超过人工处理的速度,推向极致。 生产输出效率高,让新闻事实始终跑在恐惧和谣言的前面。
3,写作机器人可以通过统计全部数据,最终提供准确、可信的统计信息。相比于人工智能处理统计样本的可信度大大提高。
4,它能解放人的劳动力,让人在更多自己适合的领域中发挥自己的价值、提升人的效率,让其可以从事更具有创造性和挑战性、拓展性工作。
5,个性化内容生产,让每个人看到自己爱看的需要看的内容以自己喜欢的风格只消费自己喜欢风格展现。过去的内容生产是为千百万人生产同一内容产品;新的出版模式下,则是为每一个单一的客户,无论个人还是集体,提供个性化的定制内容产品。
6,机器人帮助人类发现报告和发现线索、发现有趣的故事。通过机器人技术对大量的数据和信息进行分析再加工,能发现很多新奇的角度和线索,发现信息内容、新闻事件中意想不到的趋势。
7,尽管通过机器人能产生的令人信服的捏造图像、视频和声音,但是作弊、虚假、恶意攻击的识别技术一样成长快速度,世界是两面的,造假和识别虚假,相克相生。
**机器人写作还有哪些问题**
其一,公开数据和私有数据的访问边界,隐私和服务价值的调和。
没有充分的数据输入,没有大数据采集和挖掘、分析系统的支撑,算法是无法学习理解、并不能有效地写作,机器自动写作就成了无源之水、无本之木。
有充分数据的输入,则会导致输入数据在私有和公有的界限较难有区分度,要么很隔离,那就很难有关联。私有数据和公有数据彻底打通,那有涉及很多个人隐私的风险。曾经李彦宏说跟英国首相布朗(Gordon Brown)有一个挺有意思的争论,关于搜索引擎的,他说“我是知道很多关于你的信息,但我不知道你是谁,我也不会用我掌握的信息对你造成伤害。”实际情况是,但是在网络空间里,技术已经能实时追踪他并且给他发送你想要他看的、影响他行为决策的信息,机器在塑造人。
其二,即使现在有足够大的数据集,其实都还是沧海一粟,GPT2,训练语料用了800万,只是每天搜索收录的4%。每天内容输入对于机器人能够获得的数据目前仍是一个局部,这个局部就会导致偏差。就像我们物理世界,一直强调的信息对称和认知偏差一样,算法、机器人在这个层面上也会是这个问题。
第三点,机器人能够写出流畅的问题,表达出一定的观点、理解能力。但是还是无法实现对情绪、风格的把握,无法从文字表述上透露出语言、情感之美。
目前每个主打“机器写作”能力的平台基本都拥有各自的技术团队、对数据的解读和认知,产品化产业化并且能为社会贡献价值层面上,大家有不同的理解、不同的认知和想法,这一点,必将让这个事情走向多样化、多元化。
最后一点,我特别焦虑地在思考一个问题,如果机器人都能完备写作、创作了,还写作干什么呢?
标签: 算法辅助写作, 写作机器人, AI